오늘도 대회 코드를 가져왔다.
하루단위로 추출된 데이터들을 연도별로 묶어서 표현하는 방법과
Column들의 상관관계를 파악하는 방법을 알아보고자 한다.
두 방법 모두 아주 간단하니 가볍게 보면 될 듯 하다.
strftime 함수를 이용해 4자리 연도 숫자를 문자열로 바꿔주는 작업을 한다.
|
1
|
kospi['year'] = kospi['Date'].dt.strftime('%Y')
|
cs |
평균값으로 groupby 함수를 사용해 묶어준다음
활용하고 싶은 부분부터 다시 데이터프레임을 정의해준다.
|
1
2
3
|
year_m = kospi.groupby('year').mean()
kospi_for_news = year_m[9:]
kospi_for_news
|
cs |

이제 이 데이터프레임을 토대로 저번시간에 알아보았던 분석을 진행 할 수 있다.
google이라는 데이터프레임은 날짜에 따른 분야별 뉴스 개수를 나타낸다.
'society', 'politics', 'economy' 이렇게 세 가지로 나누었고
상관분석 결과는 다음과 같다.
|
1
2
3
|
import seaborn as sns
fig = plt.figure(figsize=[10,10])
ax = sns.heatmap(google.corr(),annot=True,square=True)
|
cs |
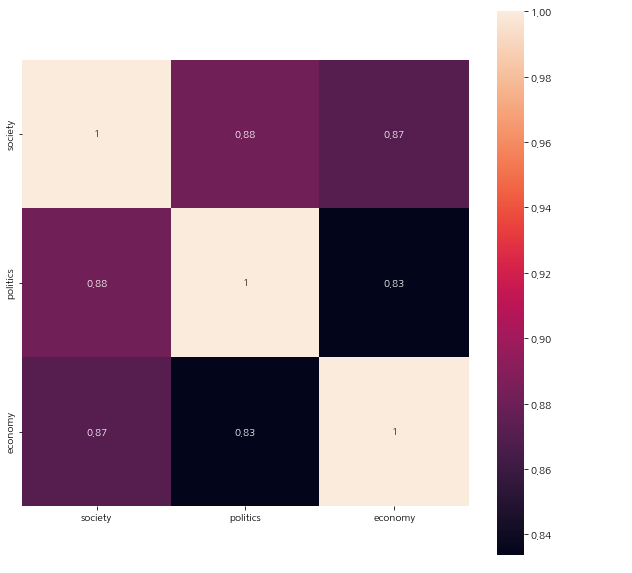
세 분야 모두 높은 상관관계를 가지고 있지만
politics와 society가 가장 높은 상관성을 지니고 있음을 알 수 있다.
조금 더 다양한 Column에 부가적인 요소들을 추가하면 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import seaborn as sns
fig = plt.figure(figsize=[15,15]) #크기
ax = sns.heatmap(news1.corr(),
annot=True, fmt='g', #상관계수 표시, 소수점 자리
linewidths = 1, #굵기
linecolor = 'white', #색깔
cmap='Blues') #색 계열
#이 밖에도 square = 'True', cbar(수치 정도 막대 출력여부) ='True' 등이 있음
plt.title('분야별 뉴스 개수의 상관관계(1)', size = 15) #제목
|
cs |
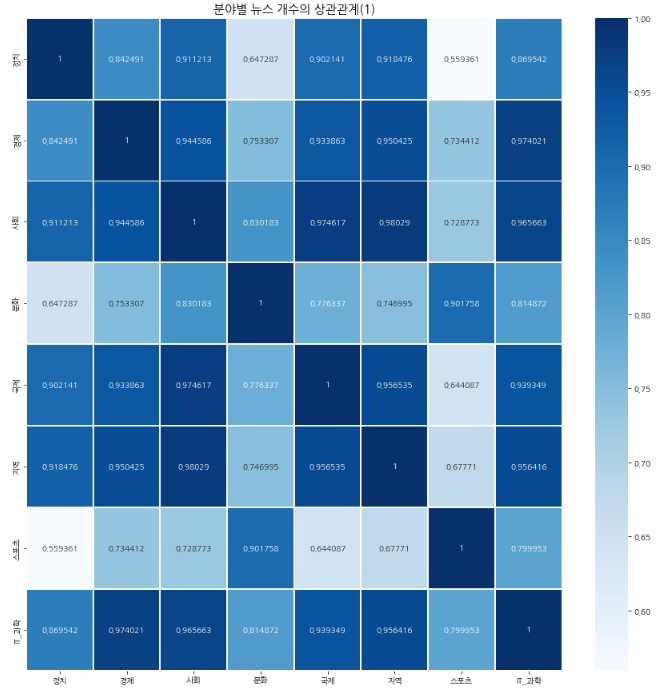
그 동안 Python 기반 기본 시각화는 많이 우려먹었으니
더 이상은 안할 것 같다
다음엔 다시 NLP로 돌아와보겠으!
'데이터 사이언스 공부 > Competition' 카테고리의 다른 글
| '제 4회 소방안전 빅데이터 활용 및 아이디어 경진대회' 데이터 활용 최우수상 후기 (4) | 2024.11.18 |
|---|---|
| matplotlib 그래프 시각화 실습 2 (y축 이중 레이블, 다중 그래프) (0) | 2022.10.04 |
| matplotlib 그래프 시각화 실습 (특정 구간 표시 하는 법) (0) | 2022.10.03 |
| 영화 관객수 예측 모델 실습 (feat. 데이콘 대회) (0) | 2022.09.16 |




댓글