이전 블로그에 업로드 했던 글을 가져와봤다.
다시 작성하기 귀찮아서 복붙!
논문선정이유
자연어 처리 관련 논문을 리뷰해야겠다고 생각하고 (항상 시작이 어렵지.. )
전반적인 자연어 처리 최근 동향에 대한 파악의 필요성을 느껴 관련 논문들을 서치해본 결과
Tom Young외 3인이 저술한 'Recent Trends in Deep Learning Basaed Natural Language Processing'을 선택하게 되었다.
사진 설명을 입력하세요.
사진 설명을 입력하세요.
정해진 논문 리뷰 순서가 정설적으로 존재하는 건 아니지만
리뷰할 논문이 새로운 이론을 소개하는 연구 형식이 아니기 때문에
본 논문의 순서와 유사하게 요약 리뷰를 진행할 것이고
아직 논문에 나오는 모든 개념과 용어들을 이해하고 있는 것이 아니기에 최대한 간단하게 그리고
중간중간 등장하는 어려운 개념들은 차차 하나씩 복습해갈 예정이다.
그럼 시작!

Abstract
딥 러닝 방법은 여러 처리 계층을 사용하여 데이터의 계층적 표현을 학습하고 많은 영역에서 최신 결과를 생성했다.
그 중, 최근 자연어 처리(NLP)의 맥락에서 다양한 모델 설계와 방법이 만개하고 있다.
이 논문에서는 수많은 NLP 작업에 사용된 중요한 딥 러닝 관련 모델 및 방법을 검토하고 진화 과정을 살펴본다.
또한 다양한 모델을 요약, 비교 및 대조하고 NLP에서 딥 러닝의 과거, 현재 및 미래에 대한 자세한 이해를 제시한다.
Introduction
자연어 처리(NLP)는 인간 언어의 자동 분석 및 표현을 위한 이론 기반의 기술 범위를 말한다.
현재 NLP 연구는 문장 분석에 최대 7분이 소요되는 일괄 처리 시대에서 Google과 같이 수백만 개의 웹 페이지를 1시간 이내에 처리할 수 있는 등의 시대로 발전했다.
NLP를 통해 컴퓨터는 구문 분석 및 품사(POS) 태깅에서 기계 번역 및 대화 시스템에 이르기까지 모든 수준에서 광범위한 자연어 관련 작업을 수행할 수 있다. 딥 러닝 아키텍처와 알고리즘은 이미 컴퓨터 비전 및 패턴 인식과 같은 분야에서 인상적인 발전을 이루었고 이러한 추세에 따라 최근 NLP 연구는 이제 새로운 딥 러닝 방법의 사용에 점점 더 초점을 맞추고 있다.
딥 러닝은 다단계 자동 기능 표현 학습을 가능하게 한다. 그 반대로, 전통적인 기계 학습 기반 NLP 시스템은 손으로 만든 기능에 크게 의존하며 이러한 손으로 만든 기능은 시간이 많이 걸리고 종종 불완전하다.
따라서 그 이후로 어려운 NLP 작업을 해결하기 위해 수많은 복잡한 딥 러닝 기반 알고리즘이 제안되었다. 논문에서는 CNN(Convolutional Neural Network), RNN(Recurrent Neural Network), Recursive Neural Network와 같은 자연어 작업에 적용되는 주요 딥 러닝 관련 모델 및 방법을 검토한다. 또한 기억 강화 전략, 주의 메커니즘 및 비지도 모델, 강화 학습 방법 및 최근에 언어 관련 작업에 심층 생성 모델이 어떻게 사용되었는지 논의한다.
1. 분산표현
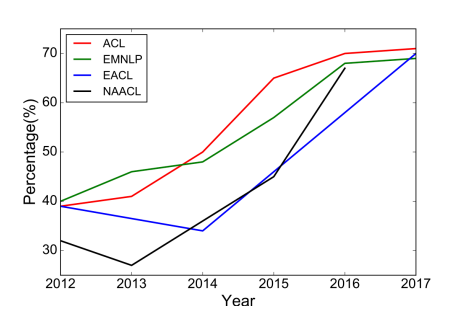
<6년간 딥러닝 논문 비율>
분산표현은 쉽게 말해 자연어를 벡터화하는 것이다.
논문에서는 차원의 저주 떄문에 저차원 공간에 존재하는 단어의 분산표현을 학습하려는 연구가 많았다고 한다.
1)Word Embeddings
word embeddings은 distributional hypothesis(비슷한 맥락에서 등장하는 단어들은 유사한 의미를 가짐)를 따르는데
따라서 주변 단어의 특성을 포착하려고 한다.
벡터들이 단어 간 유사성을 내포하고 있기에 유사도 측정 지표(ex.코사인 유사도)로 벡터간 유사성을 확인할 수 있다.
임베딩 벡터를 생성하는 모델은 오랫동안 shallow한 neural networks였지만 딥러닝 기반의 자연어처리 모델에서
깊은 구조의 neural networks가 필수적이게 되었다.
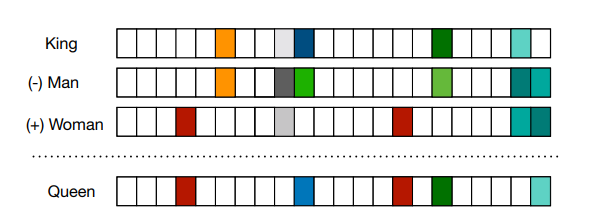
<차원 벡터로 표현되는 분포벡터>
word embeddings의 핵심은 문맥(context)를 통해 학습된다는 것이다.
이런 발전은 토픽모델과 언어모델의 탄생을 만들었다.
그 밖에도 여러 모델들이 임베딩을 기반으로 만들어졌다.
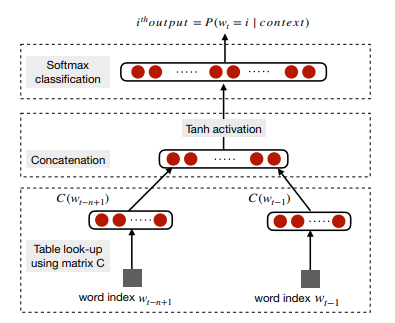
<Neural Language Model, C(i) is the i th word embedding>
2)Word2Vec
WordCBOW와 skip-gram이 있는데 요약하자면 CBOW는 주변단어로 중심단어의 조건부 확률을 계산하여 예측,
skip-gram은 중심단어로 주변단어를 예측한다.
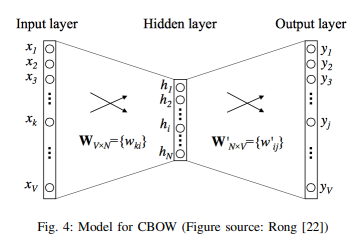
<Model for CBOW>
word embeddings은 여러가지 한계가 있는데 먼저, 두개 이상의 단어가 개별 단어들로 표현될 수 없다는 점이 있다.
이는 word coocurrence(동시등장단어)가 나오는 구문을 별도로 학습시키거나 n-gram embedding을 직접적으로 학습시키는 방벙으로 해결할 수 있다.
또 주변 단어의 small window안에서만 embedding을 학습하는 한계가 있는데 이는 bad와 good같은 단어가 같은 embeedding을 공유한다는 문제를 발생시킨다. 이는 감성분석 등의 성능 저하로 이어지고 sentiment specific word embedding(SSWE)를 통해 해결할 수 있다.
3)Character Embeddings
word embeddings은 문법적이나 의미적 정보를 포착할 수 있지만 품사태깅이나 개체명 인식같은 경우 단어 내부의
형태나 정보 즉 문자 수준에서의 이해가 매우 중요하다.
character embeddings는 words는 개별 문자의 결합이기에 the unkown wrod(등장하지 않았던 단어) 문제에 대처하기 쉽다.
따라서 words의 의미가 문자들의 합성에 의한 언어(중국어) 에서는 , word segmentaition을 피하기 위해 character embedding을 선호하는 편이다.
4)Contextualized Word Embeddings
ELMo가 핵심인데 이건 따로...
2. CNN (CONVOLUTIONAL NEURAL NETWORKS)
word embeddings이 유명해진 이후 n-gram으로 부터 상위 수준의 특징들을 추출하는 함수의 필요성이 증가했다.
CNN은 자연스러운 선택이었다.
1) basic
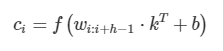
사진 설명을 입력하세요.
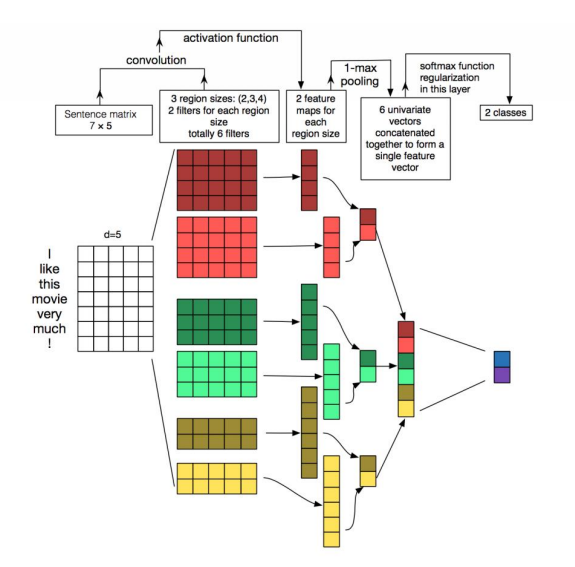
<CNN modeling on text>
또한 convolution layer에선 max-pooling 이 뒤따르는데
이는 새로운 c에 대해 최대값을 적용하여 input을 subsampling하는 전략이다.
이 전략은 필터 크기와 상관없이 input값을 고정된 차원 output으로 매핑할 수 있기에, 그리고
문장 전체에서 가장 두드러진 n-gram의 특징을 유지하면서 output의 차원을 줄일 수 있기에 사용된다.
2) application
문장분류 문제에서의 CNN활용, 감성분석 문제에서의 CNN활용이 주로 있고 기계번역에는 적합하지 않다.
전반적으로 의미적 단서를 추출하는데 효율적이지만 많은 데이터와 학습 parameters를 필요로 한다.
또한 sequential한 순서를 보존할 수 없다.
3. RNN (RECURRENT NEURAL NETWORKS)
RNN은 순차적인 정보를 처리한다. 이전에 계산한 'memory'를 가지고 현재 처리 과정에서 사용하게 된다.
이런 방식으로 language modeling(언어 모델), machine translation(기계번역), speech recognition(음성인식), image captioning(이미지캡셔닝)과 같은 NLP task에 활용되고 있다.
1)RNN의 필요성
앞서 말했듯이 데이터를 순차적으로 처리하기 때문에 문자, 단어, 문장에서 고유한 순차적 특징을 잘 포착한다.
즉 언어의 단어는 이전 단어를 기반으로 의미를 발전시키기에 이러한 context dependencies(문맥의존성)을 모델링하기위해 필요성이 부각되었다. 또한 RNN은 매우 긴 문장, 문단, 문서를 포함한 다양한 텍스트를 모델링할 수 있기에 순차적인 모델링에 적합하다는 특성을 지니고있다.
2) RNN구조
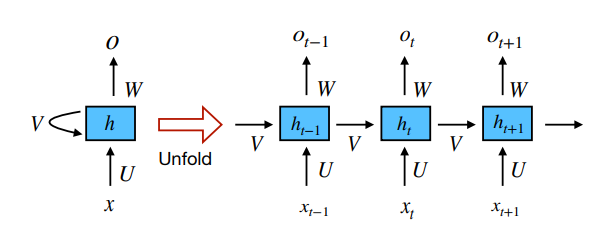
<Simple RNN network>
논문에서 나오는 위 그림과 식이 조금 다른거 같은데
(같은 논문인데..)
식에서의 W가 그림에서의 V이고, 식의 st가 그림에서 ht
RNN의 hidden state는 다른 시간 단계에서 정보를 축적하는 메모리 요소로,
가장 중요한 요소로 간주되는데 실제 단계에서는 vanishing gradient 문제를 겪고 있다.
이 문제는 RNN 변형인 long short-term memory(LSTM), gated recurrent units(GRUs)로 극복되었다.
LSTM에는 basic RNN에 'forget' 게이트가 추가되어 있다.
다음과 같은 방정식에 의해 input, forget, outpur gates를 조합하여 hidden states를 계산한다.
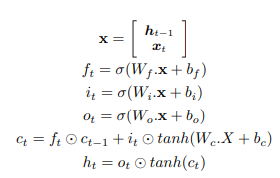
<LSTM 계산식>
GRU는 reset gate, update gate로 구성되며, 메모리 유닛이 없는 LSTM처럼 정보의 흐름을 처리한다.
따라서 전체 내용을 제어 없이 노출하고 덜 복잡하기 때문에 LSTM보다 효율적일 수 있다.
그 작업 식은 다음과 같다.
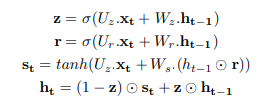
<GRU 계산식>
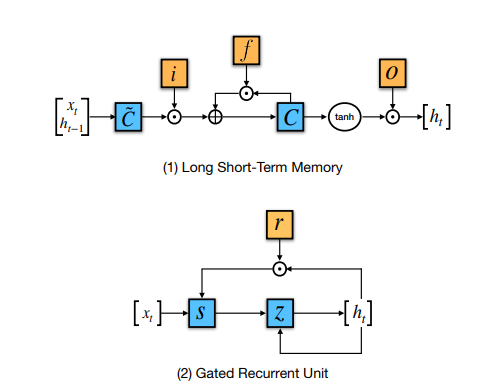
<LSTM과 GRU>
3) Applications
개체명 인식, 언어 모델링, 문자 기반의 표현 사용 등 단어 수준 분류를 위한 RNN,
SNS 문장 처리, 대화 시스템 등 문장 수준 분류를 위한 RNN,
decoder 기능을 가지고 있는 문장 생성을 위한 RNN 등으로 다양하게 연구되고 활용되는 추세이다.
4) Attention Mechanism
기존에 encorder-decoder 프레임워크다 직면한 잠재적인 문제는 완전히 관련없는 정보를 인코딩 하는 경우가 있다는 것이다.
또한 입력이 길거나, 정보가 매우 많아 선택적으로 인코딩이 불가능한 문제도 발생할 수 있다.
예를들어, 문서 요약이나 기계 번역 같은 경우 input값은 original text, output값은 축약된 값으로 해결하는데
길이가 천차만별로 다른 정보를 고정 크기로 incording하기 어렵다.
input text와 output text 사이에 특정적인 정렬(alignment)이 존재하는데 이는 각 token의 생성 단계가
input text의 특정 부분과 관련이 있음을 뜻한다.
Attention Mechanism은 decorder가 input sequence를 다시 참조할 수 있도록 하여 위의 문제를 완화하려고 한다.
특히 decording 동안 마지막 hidden states 및 생성 token 외에도 decorder은 "context" vector에 의해 조정된다.
Bahadanu et al은 Attention Mechanism은 특히 긴 sequence에 대해 성능 향상을 이끌어 냈다.
그 연구에서 attention signal 는 decoder의 마지막 hidden states에 의해 multi-layer perceptron(다층퍼셉트론)으로 결정된다.
각 decoding 단계에서 input sequence에 대한 attention signal을 시각화 하여 소스 언어와 대상 언어간의 명확한 정렬을 입증하였다.

<Word alignment matrix>
Transformer는 나중에..
4. RECURSIVE NEURAL NETWORKS
이전 RNN(recurrent nerual networs)은 순차적으로 모델링하는 자연스러운 방법이다.
하지만 언어는 words와 하위 구문이 계층적 방식으로 결합되어있는 recursive(재귀) 구조를 나타낸다.
이러한 구조는 constituency parsing tree로 나타낼 수 있기에 구문 해석을 더 잘 활용하기 위해 tree-structured 모델이 사용되었다.
(1) basic
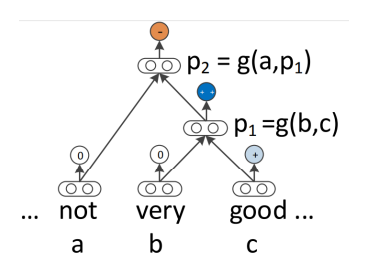
<Recursive Neural Networks>
네트워크 g는 더 높은 수준의 구(p1 or p2)의 표현을 계산하기위해 구성 함수를 정의한다.
그 형태 중 가장 간단한 형태로 다음과 같이 정의 된다.
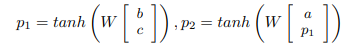
사진 설명을 입력하세요.
(2) Application
Recusive neural networks의 자연스러운 적용 중 하나는 구문 분석이다.
구문 수준 감정 분석, 문장의 명사 혹은 메시지 들 간의 인과 관계 등에 이 모델을 적용할 수 있다.
또한, LSTM은 이런 트리구조에도 적용되었고 감정 분석 및 문장 관련성 테스트에서 선형 LSTM 모델보다 향상된 성능을 보여준다.
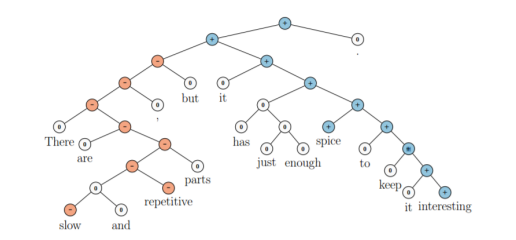
<Recursive neural networks applied on a sentence for sentiment classification>
5. DEEP REINFORCED MODELS AND DEEP UNSUPERVISED LEARNING
(1) 문장생성을 위한 reinforcement learning
Reinforcement learning은 개별적 행동을 수행하도록 훈련시키는 방법이다.
NLP에서 언어 생성 관련 작업은 reinforcement learning 문제로 연결될 수 있다.
원래의 RNN 언어 생성 모델에서는 일반적으로 현재의 hidden state와 이전의 token이 주어졌을 때 그에 맞는 정답 word가
나타날 likelihood를 최대화 하는 방안으로 학습을 진행한다.
그러나 inference 과정에서 'expose bias'라 불리는 훈련과 inference 간의 불일치는 오류를 생성한다.
또한 학습 목표가 test 지표와 다르다는 문제가 있다.
이러한 문제들을 reinforcement learning으로 해결 할 전망을 제공한다.
여러 시퀀스 생성 작업(텍스트 요약, 기계 번역 등)에 대해 RNN기반 모델을 훈련하여 성능을 개선시키기도 하였다.
생성 모델인 RNN은 에이전트로서 다음 단어를 예측하는 작업을 선택하고 내부 상태(hidden state)를 업데이트 하며
sequence의 끝에 도달하면 보상을 탐색하는데 이 보상은 특정 작업에 맞게 조정된다.
하지만 reinforcement learning에는 잘 알려진 두 가지 단점이 있다.
첫 번째는 reinforcement learning을 다루기 쉽게 만들려면 state와 action 공간을 주의 깊게 다루어야 하며, 이는 결국 모델의 학습능력과 표현력을 제한할 수 있다.
두 번째는, 보상 기능을 훈련해야 하는 필요성이 모델을 실행할 때, 설계하고 측정하기 어렵게 만든다.
(2) 비지도학습 기반 문장의
word embeddings 처럼 분산 표현도 비지도 방식으로 학습될 수 있다.
이러한 비지도 학습은 어떤 문장의 의미와 구문의 속성을 캡처할 수 있는 고정 크기 벡터에 매핑하는 'sentence encoders'로
결과를 만들어 낸다. word embeddings 학습을 위한 skip-gram 모델처럼 문장 표현 학습을 위해 skit-thought 모델이 제안되었다. 이 학습 작업에는 seq2seq 모델이 사용되었다.
6. MEMORY-AUGMENTED NETWORKS
attention mechanism은 encoder내 일련의 hidden 벡터들을 저장하며 decoder는 각 토큰을 생성하는 동안 이 벡터에엑세스 할 수 있다.
여기서 encoder의 hidden 벡터는 모델의 "내부 메모리"항목이라 볼 수 있다.
최근에는 모델과 상호작용할 수 있는 일종의 메모리와 신경망을 결합하는데에 관심이 급증하고 있다.
질의응답을 위해 메모리 네트워크 모델이 제안되었고 차후에는 더 확장하여 attention mechanism을 통해 'soft'하게 학습하도록 하는
'end-to-end memory network'가 제안되었다. 또한 언어 모델링 분야에서는 문장의 각 단어들을 메모리 항목으로 간주하여 deep LSTM모델과
견줄만한 결과를 내기도 하였다.
7. PERFORMANCE OF DIFFERENT MODELS ON DIFFERENT NLP TASKS
(1) POS tagging (품사 태깅)
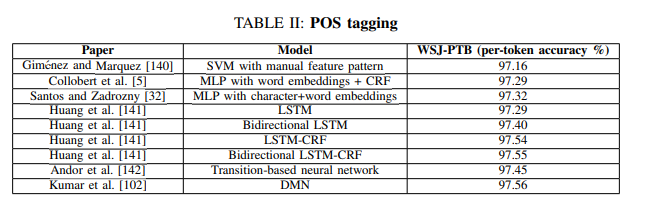
사진 설명을 입력하세요.
메모리 네트워크 중 하나인 Dynamic Memory Networks, DMN은 RNN의 각 hidden states를 메모리 항목으로 처리하여 context에 여러번 집중할 수 있게 한다.
(2) Parsing (구문분석)

사진 설명을 입력하세요.
Parsing에는 두 가지 타입이 있다. 하나는 개별 단어를 그들의 관계와 연결하는 dependency parsing(의존구문분석)이고, 텍스트를 반복적으로 하위 구문으로 분해하는 constituency parsing(구성요소분석)이 있다.
(더 많은 것들이 있지만 생략하고)
(3) Sentiment Classification (감성분석)
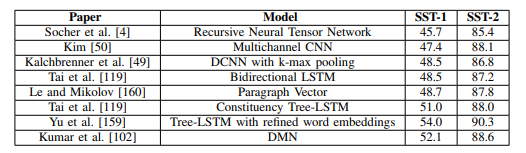
사진 설명을 입력하세요.
(4) Machine Translation

사진 설명을 입력하세요.
(5) Question answering
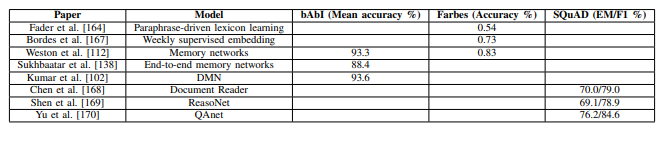
사진 설명을 입력하세요.
(6) Dialogue Systems
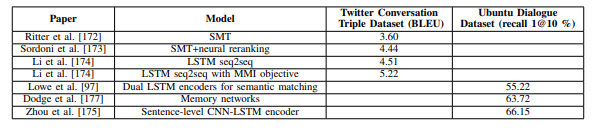
사진 설명을 입력하세요.
8. Conclusion
Deep learning은 직접 엔지니어링을 거의 수행하지 않고도 많은 양의 계산과 데이터를 활용할 수 있는 방법을 제공한다.
분산 표현을 통해 다양한 심층 모델들이 NLP 문제에 대한 새로운 최첨단 방법이 되었다.
Supervised learning은 최근 NLP 관련 deep learning 연구에서 가장 인기있는 방법이다.
그러나 특정 경우 데이터가 부족하거나 새로운 class가 나타났을 시 학습을 새로 해야하는 등의 문제가 있다.
따라서 앞으로 label이 지정되지 않는 데이터를 잘 전달하는 방향으로 deep learning기반 NLP연구가 진행될 것이라고 기대된다.
기계학습에 기대어 과거경험을 바탕으로 좋은 추측을 하는것은 좋은 방법이다.
의사결정 과정은 확률적이지만 자연어 이해에는 더 많은 것이 필요하다.
Noam Chomsky의 말을 빌려 마무리 하자면
“you do not get discoveries in the sciences by taking huge amounts of data, throwing them into a computer and doing statistical analysis of them: that’s not the way you understand things, you have to have theoretical insights”
후기
어찌저찌 첫 논문 리뷰를 진행했는데 이 논문이 여러 연구를 소개하는 논문이라 자세한 이론적, 실험적 설명보다는
해당 이론과 모델을 제시한 교수와 그 논문을 간단히 소개하고 넘어가는 경우가 많았다.
하지만 난 전반적인 자연어 처리 연구의 흐름을 알아보기 위해 이 논문을 리뷰한 것이므로 한줄 한줄 마다 그 이론을 제시한 연구와 교수님을 소개하는 것 보다는 그 과정과 전반적인 방향 위주로 알아보았던 것 같다. (그래서 생략한 것도 많고 요약한 것도 많다...)
처음이라는 것에 의의를 두고 싶고 다음에는 조금 더 나아진 논문 리뷰를 진행하고 싶다.
다음 주 내에 고고 (여러 일들을 하면서 첫 리뷰가 2주 정도 걸렸으니.. 이번엔 1주..)

'자연어처리 > 기타' 카테고리의 다른 글
| ChatGPT 벌써 업그레이드! Open AI 무려 'GPT-4' 공개 (0) | 2023.03.15 |
|---|---|
| 깃허브(Github) 파일 및 폴더 추가하고 삭제하는 법 (0) | 2023.03.02 |


댓글