어쩌다보니 전남대학교에서 주최하는 감정인식 경진대회를 참여했다.
물론 대회가 크다보니까 나 같은 초보자는 참가하는데 의의를 두고 실습 경험을 쌓고자 도전해 보았다.

본격적으로 프로젝트에 참가하기 전
오늘은 간단한 수준의 전처리를 통해 이전에 사용했던 토크나이징을 복습해봤다.
일단 주어진 데이터를 확인해보았다.
|
1
2
3
4
|
import pandas as pd
train = pd.read_csv('C:/Users/비밀/NLP/KERC22Dataset_PublicTest/train_data.tsv',delimiter='\t')
test = pd.read_csv('C:/Users/비밀/NLP/KERC22Dataset_PublicTest/public_test_data.tsv',delimiter='\t')
train
|
cs |

'context' 컬럼은 결측치가 많고 scene별로 내용이 같아서
어차피 토크나이징이 목적이었기에 'sentence'컬럼만을 가지고 전처리를 진행했다.
일단 한글만 남겨두고 제거하긴 했는데 '?' 같은 특수문자가 결과값에 영향을 미칠 수 있기에
나중에 성능을 비교해보려고 한다.
|
1
2
|
train['sentence'] = train['sentence'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
test['sentence'] = train['sentence'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
|
cs |
한글 자연어처리 패키지인 konlpy를 설치하고 그 중 okt를 통해 진행해 보았다.
먼저 okt.morphs를 통해 형태소 단위로 문장을 각각 추출한 다음
'tk_sentence'라는 새로운 column으로 넣어주는 함수를 정의하고
train에 적용하였다.
|
1
|
pip install konlpy
|
cs |
|
1
2
|
import konlpy
from konlpy.tag import Kkma, Komoran, Hannanum, Okt
|
cs |
|
1
2
3
4
5
6
7
8
9
|
okt = Okt()
tokenized = []
def token(dataframe):
for sentence in dataframe['sentence']:
tokens = okt.morphs(sentence)
tokenize = " ".join(tokens)
tokenized.append(tokenize)
dataframe['tk_sentence']=pd.DataFrame(tokenized)
token(train) |
cs |
다음엔 okt.pos를 통해 품사태깅을 진행한 후 태깅된 값에서
품사만 제거하여 'sentence_pos'라는 새로운 column에 넣어주었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def postagging(dataframe):
main_pos = []
for sentence in dataframe['tk_sentence']:
pos = okt.pos(sentence)
main_words = [word_pos[0] for word_pos in pos if word_pos[1] in ('Adjective',
'Noun',
'Adjective',
'Verb',
'Number',
'KoreanParticle'
)]
main_words_str = " ".join(main_words)
main_pos.append(main_words_str)
dataframe["sentence_pos"] = pd.DataFrame(main_pos)
postagging(train) |
cs |
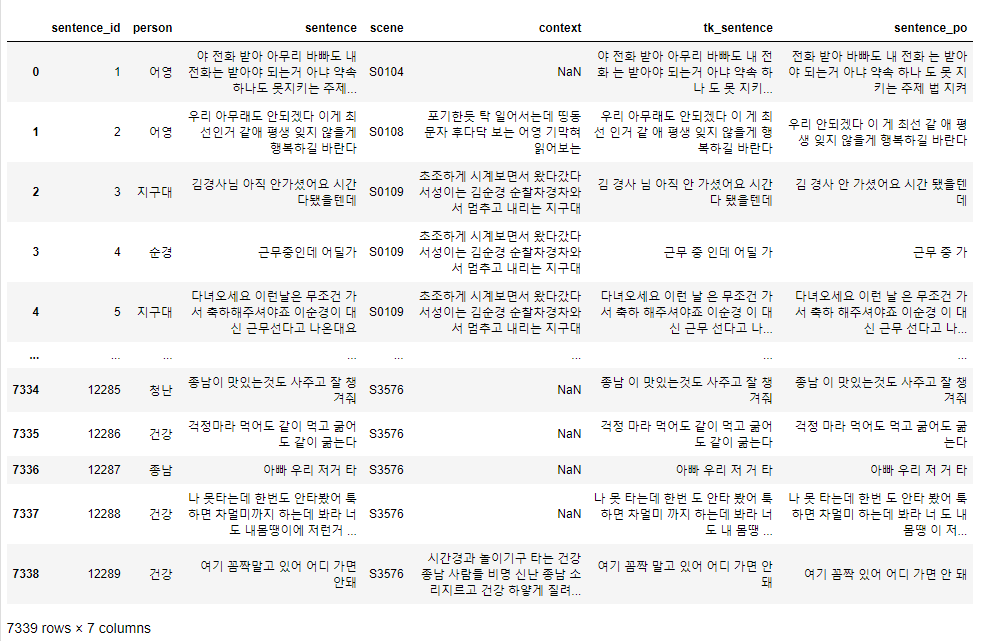
토크나이징을 완료한 결과값은 다음과 같다.
결과물을 보면 완벽한 의미대로 나눠진건 아니지만 어느정도 잘 된 것을 볼 수 있다.
사실 불용어 제거도 하려고
불용어 사전을 다운받아 리스트화 해 품사태깅 함수 정의에 넣어두려고 했는데 에러가 떠서
토크나이징 과정이 아닌 나중에 따로 불용어 처리 함수를 정의하려 진행해 봐야겠다.
|
1
2
3
4
5
6
7
8
|
stopwords = open('C:/Users/비밀/NLP/KERC22Dataset_PublicTest/stopwords.txt', 'r')
stop_words_list = []
while True:
line = stopwords.readline().strip()
if not line: break
stop_words_list.append(line)
print(stop_words_list)
|
cs |
사실 대회 가이드라인 코드가 BERT를 활용한 딥러닝 계열이라
전처리도 다른 딥러닝 패키지를 통해 진행해야할 것 같은데
그래도
복습 느낌으로 진행해봤다!
KoBERT로 돌아와보겠으!
꿑
'자연어처리 > 실습' 카테고리의 다른 글
| 대화 텍스트로 감정 예측하기 대회 실습 (1) (0) | 2022.09.23 |
|---|---|
| 한국 대중 가요 가사 분석 프로젝트 (1) 빈도 분석 (0) | 2022.09.18 |
| LSTM 모델 간단 실습 (0) | 2022.09.11 |
| Topic Modeling 및 Crawling 실습 (뉴스 데이터) (1) | 2022.09.09 |
| NaiveBayes Classifier (나이브베이즈 분류기) 실습 (2) | 2022.09.08 |




댓글