Transformer는 구글의 'Attention is all you need' 논문에서 나온 개념이다.
(조만간 논문도 읽어볼 예정...)
Transformer는 앞서 봤었던 Attention들로 이루어진 인코더와 디코더 구조를 지닌 모델로
우수한 성능을 보여주고 있다.
본격적으로 살펴보자면
Transformer 모델은 전체적으로 인코더 + 디코더 형태로 다음과 같은 모습인데

먼저 인코더를 기준으로 살펴 보겠다.
1) Positional Encoding
모델을 보면 임베딩된 벡터를 인코더에 넣기 전 Positional Encoding이라는 과정을 거치는데
Positional Encoding은 sequential한 정보를 반영하게끔 해주는 역할을 한다.
Self Attention의 경우 순서 정보를 반영하지 못하기에 순서 별로 dimension값 중 하나씩 일정 값을
더해주어 unique하게 만든다.
이렇게 되면 같은 단어라도 문장 내 위치에 따라 임베딩 벡터값이 달라지게 된다.

(Positional encoding 설명 그림)
2) Multi-head Attention
인코더 층 개수는 하이퍼파라미터 값이지만 논문에서는 6개를 사용하였다.
하나의 인코더 층은 2개의 층으로 또 나눌 수 있는데
하나는 self attetion 나머지는 feed forward 신경망이다.
먼저 인코더의 self atteintion은 앞서 배웠던 attention 개념과 동일하다.
Q,K,V 값을 구해 attention score 구하는데 Multi-head 이기에 (병렬로 여러번 하는 것이 더 효과적)
결과값을 병렬로 쌓아주고 가중치 행렬을 곱해준다.
기본적인 attention score 구하는 행렬 수식은 다음과 같다.

3) Add & Norm
multu head attention을 지나면 곧바로 Add & Norm 과정이있다.
Add는 Residual Connection(잔차 연결) 이라고도 하며
모델의 학습을 돕기 위해 attention의 input 값과 attention의 output값을 더해주는 것이다.
Norm은 Normaliation을 해주는 것인데 여기서는 batch nomalization이 아닌
Layer nomalization을 해준다.
잔차 연결이 완료된 값에 대해 하나의 layer내 여러 node의 평균과 분산을 구해
정규화를 해준다.
Add & Norm 과정은 전체적으로 학습을 안정화하고 값들의 범위를 적절하게 조정해 주는 역할을 한다.
4) Positon-wise Feed Forward Neural Network
피드 포워드 신경망은 한번의 fully connected layer을 더 두었다고 생각하면 편하다.
수식은 다음과 같다.

중간에 활성화 함수인 Relu를 지난다.
FFNN 과정의 설명 그림을 찾아보았다.
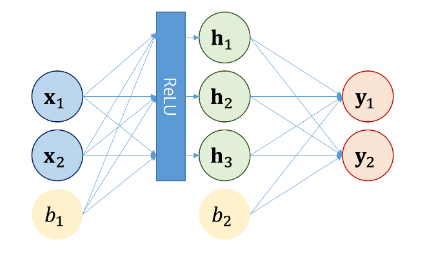
이 후 앞선 Add & Norm 과정이 한번 더 반복된다.
이번엔 FFNN에 들어가기 전 값과 후 값을 더해주고 레이어 정규화 해준다.
그다음은 디코더에 대해 알아보겠다.
디코더는 Multi-head attention이 2개 들어간다.
1) Masked Multi-head Self-Attention
'Maksed'라는 개념이 들어가는데 말 그대로 가려준다는 뜻이다.
transformer는 문장을 입력받을 때, 한번에 입력 받기에 미래 시점의 단어까지 예측에 활용될 수 있다.
학습시 미리 정답을 알려주는 것과 비슷한 문제이다.
따라서 이를 방지하기 위해 미리보기를 막는 마스크를 씌워준다.
attention score 행렬 그림으로 보면 이해하기 쉬운데


(진짜.. 원준님 상준님 매번 이해를 도와주셔서 감사합니다...)
이렇게 아직 나오지 않은 값들에 대해 softmax후 0을 취해 re nomalization을 한다.
2) multi-head attention
디코더에는 attention이 하나 더 등장하는데 이 attention의 특징은 self-attention이 아니라는 것이다.
왜냐하면 Key와 Value를 인코더 행렬로 부터 가져오기 때문이다. (Query는 디코더 행렬이다)

(디코더 과정을 간단히 표현한 그림)
이 Attention 과정도 Add & Norm 과정을 거친다.
3) FFNN, softmax
인코더와 마찬가지로 FFNN을 지나고 softmax를 취해주면 완료!
트랜스포머는 학부생활 때도 개념을 배우는게 재밌었던 모델이었는데
다시 정리하니까 또 재밌었다
다음 번엔 실습을 통해 트랜스포머 모델을 돌려보고싶다 ~
'자연어처리 > 개념 정리' 카테고리의 다른 글
| NLP Roadmap 및 평가지표 간단 개념 정리 (0) | 2022.09.20 |
|---|---|
| GPTs 간단 개념 정리 (0) | 2022.09.19 |
| Attention 간단 개념 정리 2 (0) | 2022.09.13 |
| Naive Bayes Classifier 간단 개념 정리 (0) | 2022.09.12 |
| Tokenization 전처리 간단 개념 정리 2 (0) | 2022.09.10 |




댓글